Back to Templates


Who this is for?
This workflow enables automated, scalable collection of high-quality, AI-ready data from websites using Bright Data’s Web Unlocker, with a focus on preparing that data for LLM training. Leveraging LLM Chains and AI agents, the system formats and extracts key information, then stores the structured embeddings in a Pinecone vector database.
This workflow is tailored for:
-
ML Engineers & Researchers building or fine-tuning domain-specific LLMs.
-
AI Startups needing clean, structured content for product training.
-
Data Teams preparing knowledge bases for enterprise-grade AI apps.
-
LLM-as-a-Service Providers sourcing dynamic web content across niches.
What problem is this workflow solving?
Training a large language model (LLM) requires vast amounts of clean, relevant, and structured data. Manual collection is slow, error-prone, and lacks scalability.
This workflow:
-
Automatically extracts web data from specified URLs.
-
Bypasses anti-bot measures using Bright Data’s Web Unlocker.
-
Formats, cleans, and transforms raw content using LLM agents.
-
Stores semantically searchable vectors in Pinecone.
-
Makes datasets AI-ready for fine-tuning, RAG, or domain-specific training.
What this workflow does
This workflow automates the process of collecting, cleaning, and vectorizing web content to create structured, high-quality datasets that are ready to be used for LLM (Large Language Model) training or retrieval-augmented generation (RAG).
- Web Crawling with Bright Data Web Unlocker.
- AI Information Extraction and Data Formatting.
- AI Data Formatting to produce a JSON structured data.
- Persistence in Pinecone Vector DB.
- Handle Webhook notification of structured data.
Setup
- Sign up at Bright Data.
- Navigate to Proxies & Scraping and create a new Web Unlocker zone by selecting Web Unlocker API under Scraping Solutions.
- In n8n, configure the Header Auth account under Credentials (Generic Auth Type: Header Authentication).
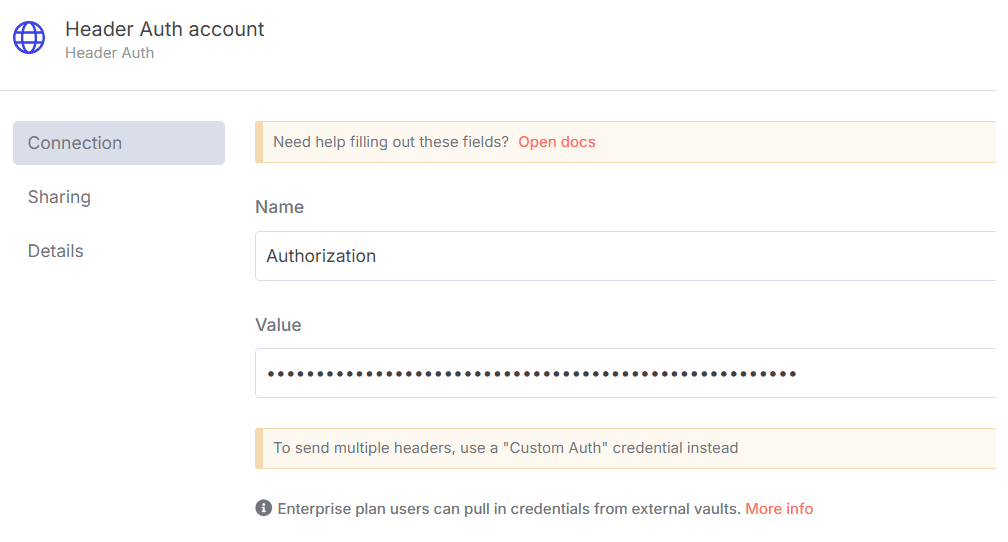
The Value field should be set with the
Bearer XXXXXXXXXXXXXX. The XXXXXXXXXXXXXX should be replaced by the Web Unlocker Token. - A Google Gemini API key (or access through Vertex AI or proxy).
- Update the LinkedIn URL by navigating to the Set LinkedIn URL node.
- Update the Set Fields - URL and Webhook URL node with the URL for web data extraction and the Webhook notification URL.
How to customize this workflow to your needs
- Set Your Target URLs. Target sites that are high-quality, domain-specific, and relevant to your LLM's purpose.
- Adjust Bright Data Web Unlocker Settings. Geo-location, Headers / User-Agent strings, Retry rules and proxies.
- Modify the Information Extraction Logic. Change prompts to extract specific attributes. Use structured templates or few-shot examples in prompts.
- Swap the Embedding Model. Use OpenAI, Hugging Face or other your own hosted embedding model API.
- Customize Pinecone Metadata Fields. Store extra fields in Pinecone for better filtering & semantic querying.
- Add Data Validation or Deduplication. Skip duplicates or low-quality content.